Quando te surge um questionamento, onde você costuma procurar a solução? Se a sua resposta for “na Internet” ou “no Google” ou até mesmo “no TikTok” (algo que pode ser bastante comum entre a geração Z[1]), você está se referindo ao uso de mecanismos de busca. Esses serviços possuem como propósito descobrir informações específicas que os usuários possam estar interessados dentro da vasta quantidade de dados disponíveis na World Wide Web (ou simplesmente web).
Os mecanismos de busca são conhecidos por diversas denominações na literatura científica, incluindo buscadores, ferramentas de busca, serviços de busca, motores de busca, entre outros. Neste estudo, utilizamos o termo “mecanismos de busca” em todo o texto para que o leitor não se confunda e possa compreender de maneira objetiva o que eles são e como funcionam. No entanto, é importante enfatizarmos que todos os termos se referem a sistemas que recuperam conjuntos de informações pertinentes para uma determinada necessidade a partir de consultas geralmente textuais.
Apesar de essa terminologia ser frequentemente empregada para descrever os mecanismos de busca que exploram a totalidade da web, também pode ser aplicada em sistemas internos para diferentes tipos de pesquisa. Podemos observar que plataformas como TikTok, Instagram e Youtube entre muitos outros sites e aplicativos possuem em suas interfaces seções dedicadas a buscas, e que embora não utilizem os mesmos critérios de ferramentas mais complexas, cumprem uma função similar. Contudo, neste texto, focaremos nos mecanismos de busca destinados à pesquisa na web como um todo, tais como Google, Bing e Duck Duck Go.
Mesmo que sejam diferentes entre si, os mecanismos de busca na web tendem a desempenhar três tarefas básicas: i) pesquisam na web ou selecionam partes dela; ii) mantêm um índice das informações que encontram e onde se encontram; e iii) permitem aos utilizadores procurar palavras ou combinações de palavras encontradas nesse índice[2]. Dessa maneira, para encontrar os resultados que visualizamos ao pesquisarmos determinada palavra ou frase, os mecanismos de busca fazem uso de três etapas: crawling (rastreamento), indexing (indexação) e ranking (ranqueamento).
A partir de um robô ou programa (como você quiser chamar) acontece o processo de rastreamento. Os spiders (aranhas) ou crawlers (rastejadores), são programas que percorrem a estrutura da superfície da web, recolhendo informações sobre itens relevantes contidos em páginas, como: título da página, palavras-chave, layout, links vinculados e mais informações presentes. Os crawlers costumam iniciar sua atividade pelos servidores mais frequentes e por sites da web que são populares. No entanto, cada um deles adota uma estratégia distinta para determinar quais páginas visitar e como se deslocar. Além disso, em razão da proteção dos modelos de negócios das big techs ou das organizações que operam esses mecanismos de busca, não há informações específicas sobre o funcionamento detalhado desses robôs. Porém, alguns estudiosos[3]mostram que muitas das vezes esses crawlers começam a pesquisa por meio de uma lista específica de documentos (chamados de endereços sementes) e, a partir dessa lista, realizam um rastreamento recursivo dos documentos utilizando as referências (links) contidas nos mesmos. As listas iniciais podem ser geradas a partir do que é considerado novo ou de sites mais populares na web, especialmente aqueles que contêm múltiplos links, acessando sua página principal e seguindo os links disponíveis nela.
Quando os crawlers acessam uma página, eles primeiro checam se já a visitaram antes ou se é uma nova[4]. Se a página já tiver sido indexada, o crawler examina se houve alguma alteração desde sua última visita e, caso tenha havido, atualiza as informações gravadas na base de dados. A maioria desses programas tem um intervalo de tempo definido para retornar aos sites que indexaram, com o objetivo de identificar alterações nesses sites[5]. Esse é um processo contínuo e ininterrupto; às vezes, os “rastreadores” desistem se o conteúdo estiver oculto ou exigir muitos cliques para ser acessado a partir da página inicial.
Depois de reunir esses itens, as informações são enviadas para uma base de dados que extraem as informações das páginas e as armazenam, dando início ao processo de indexação.[6] Para agilizar a procura por informações em seu banco de dados, esses mecanismos de busca desenvolvem um catálogo com todos os termos que podem ser usados para encontrar dados, além do URL das páginas que os incluem, em um índice. Você pode imaginar essa etapa como um sumário de um livro, onde a extensão da base de dados influencia a abrangência da pesquisa assim como o sumário define a quantidade de páginas de um livro. Quanto maior o número de documentos ou páginas armazenadas no sistema, mais resultados ele conseguirá recuperar.
A maioria dos mecanismos de busca realiza a indexação, o que significa que registra em seu banco de dados cada palavra do texto que pode ser vista nas páginas. Contudo, alguns deles capturam apenas o URL, as palavras mais comuns ou as expressões e termos mais importantes encontrados no título, nos cabeçalhos e nas linhas iniciais, por exemplo. Além disso, certos mecanismos de busca também indexam outros termos que não estão visíveis no texto, mas que contêm informações necessárias. Alguns mecanismos não consideram em seus índices algumas palavras do texto, conhecidas como stopwords (palavras proibidas no português). Essas palavras são recorrentes, como a preposição “de” ou o artigo “the” no inglês e devido à sua alta frequência nos textos, muitos desses motores optam por excluí-las de seus índices para otimizar o espaço de armazenamento. Outros, as incluem nos índices, mas as desconsideram durante a busca, visando agilizar o processo[7].
Devido à imensa quantidade de páginas disponíveis na web, normalmente encontramos um grande volume de resultados ao realizarmos qualquer busca. Para oferecer os “melhores” sites, a maioria dos motores de busca utiliza algoritmos que organizam esses resultados por meio do processo de ranqueamento[8]. Entre os critérios frequentemente empregados por esses algoritmos estão: a localização das palavras, a frequência das palavras em uma página e a proximidade entre esses termos. Por exemplo, se o termo buscado aparece no título, em cabeçalhos destacados ou nos primeiros parágrafos do conteúdo, esse material é considerado mais relevante em comparação com outros onde as palavras-chave não estão nessas posições. Além disso, se uma palavra aparece com maior frequência em uma determinada página do que em outra, a primeira será vista como mais relevante. Os motores de busca também podem considerar o tamanho de documentos presentes na URL. Quando dois documentos têm o mesmo número de ocorrências dos termos procurados, os mais curtos são vistos como mais relevantes do que os mais longos. Em algumas situações, aplica-se uma curva decrescente, onde a primeira ocorrência de um termo tem maior peso do que a segunda, que por sua vez tem maior peso do que a terceira, e assim sucessivamente.
Outro método utilizado por mecanismos de busca para realizar o ranking de páginas é o número total de vezes que uma palavra aparece na base de dados, pois há uma relação inversa entre o valor informativo de um termo e a frequência com que ele aparece em um texto. Dessa forma, as palavras recebem pesos que são inversamente proporcionais à sua frequência na totalidade dos documentos que o motor indexa. Ou seja, termos que aparecem com muita frequência tendem a ter um peso menor do que aqueles que são relativamente raros na base de dados. O método exato para determinar a importância das páginas varia de um mecanismo de busca para outro e é enquadrado como segredo de negócio opaco.
Um dos processos de ranqueamento mais populares na história dos buscadores foi o PageRank do Google que mapeia hyperlinks de entrada e saída e inspirou diversos métodos de otimização que criaram um mercado próprio, além de influenciar a lógica algorítmica de ordenamento de informações online. Nos últimos anos, os sistemas tem se complexificado com a adição de metodologias semânticas de análise de relevância e qualidade percebida, considerando temas prioritários de acordo com os parâmetros de cada empresa desenvolvedoras.
Por meio de técnicas de usabilidade, arquitetura da informação e experiência do usuário (UX), a disposição dos links na página de resultados tem um impacto significativo em onde os usuários do Google optam por clicar. A tabela a seguir (Tabela 1)[9] apresenta um resumo do mapeamento sobre a distribuição de cliques. Observa-se que aproximadamente 70% dos cliques nas pesquisas ocorrem nos três primeiros resultados, mesmo com a maioria das buscas retornando de centenas a bilhões de possibilidades.
| Recurso da página Google | Taxa de Cliques (Click through rate) |
| Anúncio – Posição 01 | 2.1% |
| Anúncio – Posição 02 | 1.4% |
| Anúncio – Posição 03 | 1.3% |
| Anúncio – Posição 04 | 1.2% |
| Resultado de Busca – Posição 01 | 39.8%[10] |
| Resultado de Busca – Posição 02 | 18.7%[11] |
| Resultado de Busca – Posição 03 | 10.2% |
| Resultado de Busca – Posição 04 | 7.2% |
| Resultado de Busca – Posição 05 | 5.1% |
| Resultado de Busca – Posição 06 | 4.4% |
| Resultado de Busca – Posição 07 | 3.0% |
| Resultado de Busca – Posição 08 | 2.1% |
| Resultado de Busca – Posição 09 | 1.9% |
| Resultado de Busca – Posição 10 (se presente) | 1.6% |
Tabela: Distribuição de cliques
No Brasil, estimativas indicam que o Google detém aproximadamente 96%[12] do mercado, tendo se tornado até mesmo uma metonímia para descrever mecanismos de busca. A companhia frequentemente se apresenta como uma facilitadora de negócios e mídias no país e em 2022, durante uma apresentação, a empresa afirmou que seus serviços — incluindo o mecanismo de busca, plataformas de anúncios, YouTube e outros — geraram um impacto econômico de 153 bilhões de reais no Brasil e atenderam cerca de 11 milhões de empresas. Sua receita global foi reportada em 307 bilhões de dólares, enquanto o lucro líquido alcançou 73,7 bilhões de dólares, conforme os relatos apresentados aos investidores[13].
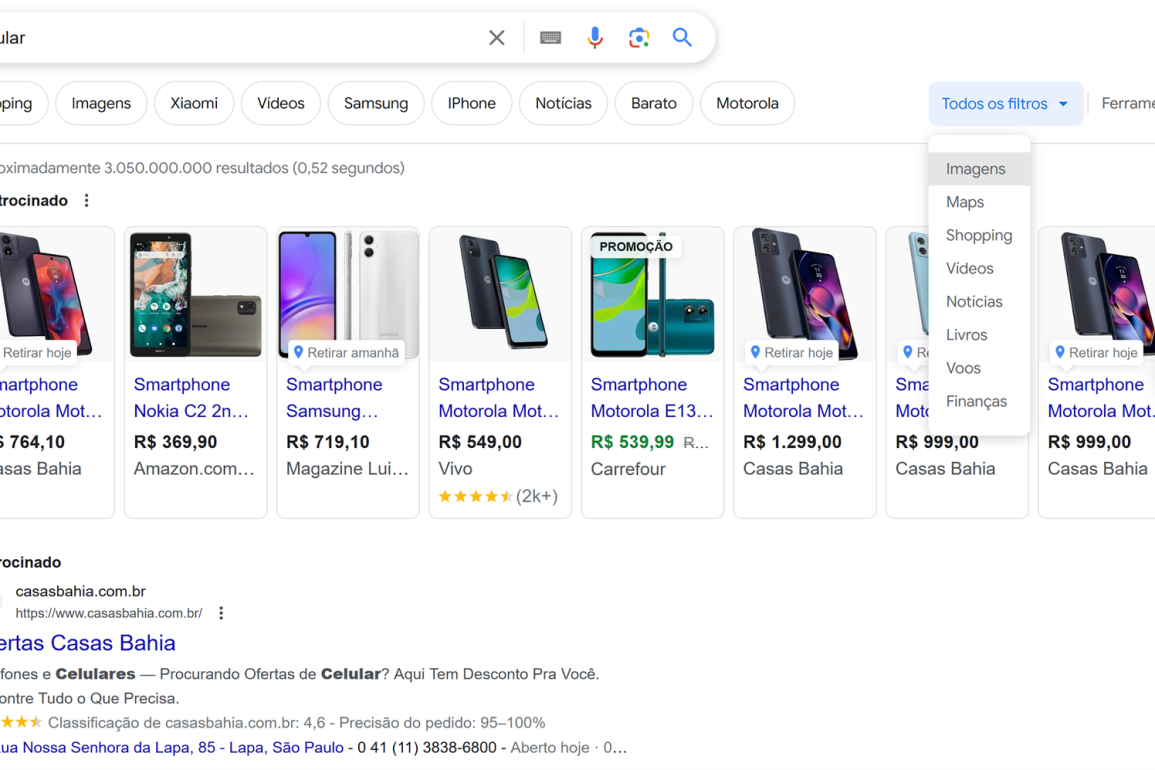
Na Figura apresentada abaixo, observa-se que a busca por um produto de consumo, o “celular”, exibe em locais de destaque não apenas os anúncios que geram receita direta para a empresa, mas também filtros de resultados relacionados a outros serviços do grupo, como “Imagens”, “Maps”, “Shopping”, “Vídeos”, “Livros”, “Vôos” e “Finanças”. Essa integração possibilita a geração de referências cruzadas entre conteúdos e atrativos para os usuários, além de fornecer dados e métricas para parceiros comerciais e informações comportamentais e demográficas para a própria empresa.

Figura: Tela do mecanismo de busca Google
Esses resultados orientam de maneira estratégica o consumo de mídia, informações e entretenimento para outras plataformas do grupo, gerando investigações antitruste[14] sobre práticas da Alphabet (empresa proprietária dos serviços Google). Em uma das apurações, as autoridades regulatórias nos Estados Unidos descobriram que a companhia desembolsou dezenas de bilhões para garantir que o Google se tornasse o mecanismo de busca padrão em navegadores e smartphones de variados fabricantes, limitando indiretamente as escolhas disponíveis para os consumidores e obtendo vantagens competitivas consideradas injustas[15]. Em relação à sua loja de aplicativos, a Play Store, a Google teve que pagar 700 milhões de dólares nos EUA como parte de um acordo antitruste devido às preferências que a plataforma oferecia aos produtos do próprio conglomerado[16].
O modo como o grupo trabalha com os dados coletados, organizados e operacionalizados em serviços rentáveis a tornou sinônimo da capacidade de corporações gigantes da tecnologia em transformar informação em conhecimento acionável. Essa capacidade é central no modo como os serviços do grupo são apresentados a seus clientes. Como exemplo, Eric Schmidt, então CEO da Google, disse já em 2010 que a “serendipidade pode ser calculada agora. Nós podemos produzi-la eletronicamente”[17]. Ou seja, a busca por identificar o que seus usuários podem considerar “serendipidade” (descobertas ou acontecimentos inesperados que ocorrem por acaso) levou o grupo a afirmar que já poderia realizar este tipo de previsão – há mais de uma década atrás. A confiança em predizer interesses de usuários é um argumento de negócio que é constantemente citado pelo grupo. A fim de exemplo, em relatório apresentado sobre a mudança de comportamento de consumidores durante a Covid19, a empresa oferece considerações sobre análises que realiza sobre “O que as pessoas fazem”; “O que as pessoas sabem”, “Como pessoas ganham dinheiro”; “Como as pessoas se sentem” e “Como pessoas aprendem” em regiões específicas[18]. Conceitos de modulação algorítmica[19] [20] [21] têm sido aplicados na literatura científica para explicar a capacidade de empresas de tecnologia, através de sistemas algorítmicos, de influenciar comportamentos em escala.
As evidências acima são só uma amostra do quanto a Alphabet e as empresas do conglomerado declaram ter domínio sobre a análise de comportamento em grande escala. Mas é importante reforçar como mecanismos de buscas como o Google tem buscado evitar transparência sobre suas decisões de desenvolvimento algorítmico e como, quando problemas emergem, representantes das empresas do grupo alegaram desconhecer os problemas, atribuíram os resultados negativos a fatores supostamente não controláveis. Empresas monopolistas como a Alphabet tem lutado contra qualquer controle social da qualidade do serviço.
Buscadores são um tipo de serviço relativamente pouco estudados, se comparados a serviços de mídias sociais como Facebook e Twitter. Quer saber mais sobre? Assine nosso boletim e receba, em breve, relatório dedicado ao tema.
[1] ALMOQBL, M. et al. “Tiktok from an entertaining application to a search engine”. 2024. Disponível em: http://dx.doi.org/10.2139/ssrn.4975339
[2] PESHAVE, Monica; DEZHGOSHA, Kamyar. “How search engines work: And a web crawler application”. 2005. Tese de Doutorado. University of Illinois Springfield.
[3] KOSTER, Martijn. “Robots in the Web: threat or treat?”. OII Spectrum, v. 2, n. 9, p. 8-18, 1995.
[4] EXPOSTO, José et al. “Um modelo cooperativo e distribuído para a recuperação de informação na WWW”. 2003.
[5] ARASU, Arvind et al. “Searching the web”. ACM Transactions on Internet Technology (TOIT), v. 1, n. 1, p. 2-43, 2001.
[6] CENDÓN, Beatriz Valadares. “Ferramentas de busca na Web”. Ciência da Informação, v. 30, p. 39-49, 2001.
[7] CENDÓN, Beatriz Valadares. “Ferramentas de busca na Web”. Ciência da Informação, v. 30, p. 39-49, 2001.
[8] ARASU, Arvind et al. “Searching the web”. ACM Transactions on Internet Technology (TOIT), v. 1, n. 1, p. 2-43, 2001.
[9] Dados de FirstPageSage: https://firstpagesage.com/reports/google-click-through-rates-ctrs-by-ranking-position/
[10] Quando apresentado no formato “snippet”, que oferece um resumo da página, chega a 42,9% segundo a projeção acima.
[11] Quando apresentado no formato “snippet”, que oferece um resumo da página, supera os 27% segundo a projeção citada.
[12] A partir de dados da Statcounter (https://gs.statcounter.com/search-engine-market-share/all/brazil) e Statista (https://www.statista.com/statistics/309652/brazil-market-share-search-engine). Mundialmente, o índice é de 92%.
[13] Disponível em: https://abc.xyz/assets/95/eb/9cef90184e09bac553796896c633/2023q4-alphabet-earnings-release.pdf
[14] A legislação antitruste tem como objetivo prevenir a criação de monopólios e outros elementos que possam afetar a livre concorrência.
[15] Disponivel em: https://www.reuters.com/technology/five-things-know-about-google-antitrust-trial-it-hits-halfway-mark-2023-10-12/
[16] Disponível em: https://www.poder360.com.br/tecnologia/google-pagara-us-700-milhoes-em-acordo-antitruste-nos-eua/
[17] Disponível em: https://www.zdnet.com/article/google-to-end-serendipity-by-creating-it/ . Tradução nossa de “serendipity can be calculated now. We can actually produce it electronically”.
[18] Disponível em: https://www.thinkwithgoogle.com/intl/en-emea/consumer-insights/consumer-trends/behavioural-change-google-search-insights/
[19] Disponível em: https://eprints.qut.edu.au/212309/
[20] Disponível em: https://journals.sagepub.com/doi/full/10.1177/1354856517736982
[21] DA SILVEIRA, Sérgio Amadeu. “A noção de modulação e os sistemas algorítmicos”. PAULUS: Revista de Comunicação da FAPCOM, v. 3, n. 6, 2019.
Autores:
Tarcizio Silva – Doutor em Ciências Humanas e Sociais (UFABC). Mestre em Comunicação (UFBA). Consultor em Direitos Digitais na ABONG/Nanet. Autor de “Racismo Algorítmico: inteligência artificial e discriminação nas redes digitais” (Edições Sesc, 2022). www.tarciziosilva.com
Vanessa Silva – Mestranda em Comunicação na Universidade Federal da Paraíba (PPGC/UFPB). Possui bacharelado em Relações Públicas pela mesma instituição (2022) e formação técnica em T.I. pela Escola Técnica Estadual Miguel Arraes de Alencar (2015). Participa do Grupo de Estudo e Pesquisa em Sociologia, Comunicação e Informação (GEPSCI/UFPB/CNPq) e desenvolve estudos baseados em práticas de comunicação e informação no âmbito da tecnopolítica, a partir da Teoria Racial Crítica (TRC). www.linkedin.com/in/vanessasilva-st
Deixe um comentário